



AI Forecasting's Catch-22: The Practical Value of Flawed Models
A Response to titotal's AI 2027 Critique

Much of the critique targets the unjustified weirdness of the superexponential time horizon growth curve that underpins the AI 2027 forecast. During my own quick excursion into the Timelines simulation code, I set the probability of superexponential growth to ~0 because, yeah, it seemed pretty sus. But I didn’t catch (or write about) the full extent of its weirdness, nor did I identify a bunch of other issues titotal outlines in detail. For example:
The AI 2027 authors assign ~40% probability to a “superexponential” time horizon growth curve that shoots to infinity in a few years, regardless of your starting point.
The RE-Bench logistic curve (major part of their second methodology) is never actually used during the simulation. As a result, the simulated saturation timing diverges significantly from what their curve fitting suggests.
The curve they’ve been showing to the public doesn’t match the one actually used in their simulations.
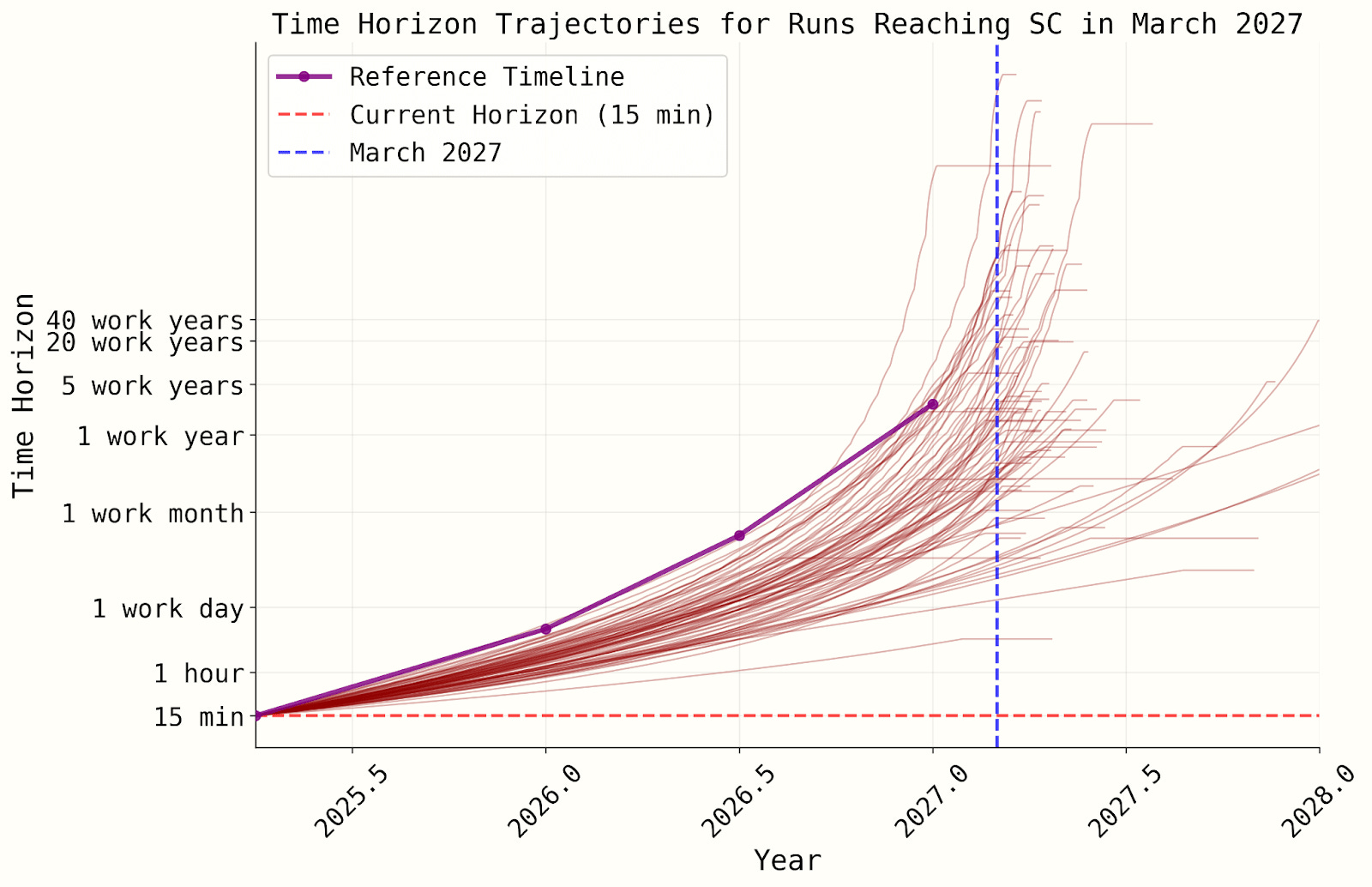
…And more. He’s also been in communication with the AI 2027 authors, and Eli Lifland recently released an updated model that improves on some of the identified issues. Highly recommend reading the whole thing!
That said—it is phenomenal*, with an asterisk. It is phenomenal in the sense of being a detailed, thoughtful, and in-depth investigation, which I greatly appreciate since AI discourse sometimes sounds like: “a-and then it’ll be super smart, like ten-thousand-times smart, and smart things can do, like, anything!!!” So the nitty-gritty analysis is a breath of fresh air.
But while titotal is appropriately uncertain about the technical timelines, he seems way more confident in his philosophical conclusions. At the end of the post, he emphatically concludes that forecasts like AI 2027 shouldn’t be popularized because, in practice, they influence people to make serious life decisions based on what amounts to a shoddy toy model stapled to a sci-fi short story (problematically disguised as rigorous, empirically-backed research).
He instead encourages plans that are “robust to extreme uncertainty” about AI and warns against taking actions that “could blow up in your face” if you're badly wrong.
On the face of it, that sounds reasonable enough. But is it?
“Robust” Planning: The People Doing Nothing
Here, it might be helpful to sort the people who update (i.e. make serious life decisions) based on AI 2027 & co. into two categories: people involved in AI safety and/or governance, and everyone else.
First, when it comes to everyone else, the real robustness failure may actually run in the opposite direction: most people are underreacting, not overreacting. In light of that, those updating in response to AI 2027 seem to be acting more robustly than the vast majority.
It’s my understanding that titotal often writes from the frame of disproving rationalists. To be clear, I think this is perfectly worthwhile. I have productively referenced his excellent piece on diamondoid bacteria in several conversations, for instance.
However, while he asserts that people ought to make plans robust to “extreme uncertainty” about how AI will go, his criticism seems disproportionately targeted at the minority of people who are, by his lights, updating too much, rather than the vast majority of people who are doing virtually nothing (and who could do something) in response to AI progress.
Here, I’d argue that “extreme uncertainty” should imply a non-negligible chance of AGI during our lifetimes (including white-collar displacement, which could be quite destabilizing). Anything less suggests to me excessive certainty that AI won’t be transformative. As Helen Toner notes, “long timelines” are now crazy short post-ChatGPT, and given current progress, arguing that human-level AI is more than a few decades out puts the burden of proof squarely on you. But even under milder assumptions (e.g. long timelines, superintelligence is impossible), it still seems implausible that the most robust plan consists of “do ~nothing.”
As I stated, I don’t precisely know what he’s referring to when he talks about people “basing life decisions” on AI 2027, but a quick search yielded the following examples:
Career pivots into AI safety
Cutting spending & increasing investment / saving
Alternatively, deferring saving & donating to alignment organizations
Temporarily delaying long-term plans (e.g. having children, starting PhDs, buying a house)
Assuming, again, that extreme uncertainty implies a decent chance of AGI within one’s lifetime, all of these seem like reasonable hedges, even under longer timelines. None of them are irreversibly damaging if short timelines don’t materialize. Sure, I’d be worried if people were draining their life savings on apocalypse-benders or hinting at desperate resorts to violence, but that’s not what’s happening. A few years of reduced savings or delayed family planning seems like a fair hedge against the real possibility of transformative AI this century.
Even more extreme & uncommon moves—like a sharp CS undergrad dropping out to work on alignment ASAP—seem perfectly fine. Is it optimal in a long timelines world? No. But the sharp dropout isn’t dipping to do coke for two years, she’s going to SF to work at a nonprofit. She’ll be fine.
Inaction is a Bet Too
Relatedly, I might be reading too much into his specific wording, but the apparent emphasis on avoiding actions (rather than inactions) seems unjustified. He warns against doing things that could majorly backfire, but inaction is just another form of action. It’s a bet too.
The alternative to “acting on a bad model” is not “doing nothing.” It’s acting on some other implicit model—often something like: “staying in your current job is usually the right move.” That might work fine if you're deciding whether to spontaneously quit your boring day-job, but it's less useful if you’re interested in thriving during (or influencing) a potentially unprecedented technological disruption.
Acting on short timelines and being wrong can be costly, sure—embarrassing, legitimacy-eroding, even seriously career-damaging. But failing to act when short timelines are actually right? That would mean neglecting to protect yourself from (or prevent) mass unemployment, CBRN risk, and other harms, leaving it in the hands of *shudders* civil society and the government's emergency response mechanisms.
This costly asymmetry could favor acting on short timelines.
The Difficulty of “Robust” Planning in Governance
Second, with respect to AI governance in particular (my wheelhouse), it’s not clear that plans “robust to extreme uncertainty” about AI actually exist. Or if they do, they might not be particularly good plans in any world.
I do know governance people who’ve made near-term career decisions informed in part by short timelines, but it wasn’t AI 2027 solely guiding their decision-making (as far as I know). That differs from what titotal says he’s seen (“people taking shoddy toy models seriously and basing life decisions on them, as I have seen happen for AI 2027”), so note that this subsection might be unrelated to what he’s referring to.
I’ve argued before that AI governance (policy in general) is time-sensitive in a way that makes robust planning really hard. What’s politically feasible in the next 2–5 years is radically different from what’s possible over 2–5 decades. And on the individual career level, the optimal paths for short vs. long timelines seem to diverge. For example, if you think AGI is a few years away, you might want to enter state-level policy or ally with the current administration ASAP. But if you think AGI is 30 years out, you might work on building career capital & expertise in industry or at a federal institution, or focus on high-level research that pays off later.
It seems hard to cleanly hedge here, and trying to do so likely means being pretty suboptimal in both worlds.
Corner Solutions & Why Flawed Models Still Matter
Earlier, I mentioned the asymmetry between short and long timelines that could favor acting on the former. Nonetheless, there is a potentially strong case to be made that in governance, the cost of false positives (overreacting to short timelines) is higher than the cost of false negatives. But it’s not obviously true. It depends on the real-world payoffs.
Since neither short- nor long-timeline governance efforts are anywhere close to saturation, neglected as they are, optimal resource allocation depends strongly on the relative payoffs across different futures—and the relative likelihoods of those futures. If the legitimacy hit from being wrong is low, the payoff from early action is high, and/or short timelines are thought to be somewhat likely, then acting on short timelines could be a much better move.
Basically, it seems like we’re dealing with something close to a “corner solution”: a world where the best plan under short timelines is quite different from the best plan under long ones, and there’s no clean, risk-averse middle path. In such cases, even rough evidence about the relative payoffs between short- and long-timeline strategies, for instance, becomes highly decision-relevant. At times, that might be enough to justify significant updates, even if the models guiding those updates are imperfect.
Conclusion: Forecasting’s Catch-22
Titotal’s specific criticisms of AI 2027 are sharp and well-warranted. But the forecast is also one of the only serious attempts to actually formalize a distribution over AI timelines and think about downstream implications. I know it’s been immensely useful for my own thinking about timelines and progress, even though I also disagree with its conclusions (and specifics).
Titotal writes that in physics, models are only taken seriously when they have “strong conceptual justifications” and/or “empirical validation with existing data.” But AI forecasting is never going to approach the rigor of physics. And if short timelines are plausible, we barely have time to try.
In fact, there’s a bit of a catch-22 here:
If short timelines are likely, we need to act fast.
But to know if they’re likely, we need good models.
Good models take time to build and validate.
But if you spend your time building the model, you’re not acting (or convincing others to act) until it may already be too late.
So you end up with this weird tradeoff: spend time improving the epistemics and delay impact, or push for action earlier but with lower certainty about actual impact. There’s no obvious answer here.
In this context, even flawed forecasts like AI 2027 can support reasonable, defensible action, particularly in governance. Under genuine uncertainty, “robust” planning may not exist, inaction is just another risky bet, and flawed models may be the best we’ve got.
In light of this, I’d be very interested in seeing titotal try to “read the tea leaves of the AI future”—I think it’d be well worth everyone’s time.
More anecdata + agreement wrt robustness for careers:
The people I know who are making big career choices in the shadow of transformative AI seem to be making choices pretty robust to uncertainty. It's more "I had an AWS SWE offer right out of undergrad, but I decided to move to the Bay and do a mechinterp startup instead," than "I'm telling everyone I love to FUCK OFF and joining a cult."
Suppose it's 2040, and Nothing Ever Happened. The person who turned down the AWS offer because she wrongly believed Something Would Happen now has no retirement account and no job (the mechinterp startup is dead; there's nothing to interpret). Where does that leave her? In the same boat as 4 in 10 Americans[1], and probably with at least one economically-useful skill. (Startups will probably still exist in 2040). She's certainly counterfactually worse off than if she'd gone to Seattle instead of the Bay... but not so worse off that I'd be comfortable calling her plans "not robust to uncertainty."
If the pivoters I know are wrong, they don't enter Yann LeCun-world with a couple embarrassing-in-hindsight substack comments and zero career capital — they enter with a couple embarrassing-in-hindsight substack comments and pretty-good career capital. Maybe titotal and I (and you) just disagree about what "robust" means?
[1] https://news.gallup.com/poll/691202/percentage-americans-retirement-savings-account.aspx
Also, the diamondoid bacteria link is broken :(
> A few years of reduced savings or delayed family planning seems like a fair hedge against the real possibility of transformative AI this century.
I think my issue with this is the assumption that we'll actually know the state of play in a few years. Obviously if AGI happens and we hit superhuman coders in 2027, we'll know by 2027. But if we don't, there's no reason to assume that we won't be having the exact same debate in 2027. It might get even worse as we get closer to AGI; for example, we can imagine a timeline in which ChatGPT almost reaches AGI in 2027 and causes significant job losses (or at least shifts in the job market) via increased automation and productivity, but doesn't manage to fully replace humans.
In that timeline, I would expect AI Doomers to be even more frantic about basing their life decisions on short timelines. But as you point out, the question is transformative AI this *century*. In that case, I think that the "just a few more years" framework is pretty problematic. At some point, you have to make an arbitrary decision to just keep living your life, and I think that will only get harder as we get "closer" to AGI.
Otherwise, great post! I particularly like the framing of inaction as a bet too—it being the default makes it no less of a choice than action.